조인 방식 (Join Method)
MS SQL에서 지원하는 조인 메소드에 대해 알아보자.
1. 들어가며
MS SQL에서 지원하는 물리적인 조인 방식에는 크게 3가지가 있다.
① 중첩반복(Nested Loops)
② 정렬병합(Sort Merge)
③ 해시매치(Hash Match)
이중 Nested Loops와 Sort Merge는 어느 DBMS든 가장 전통적인 조인 방식이고 서로간의 단점을 보완하고자 나왔다. Hash Match의 경우는 위의 두 조인 방식의 단점을 보완하고자 나온 방식이다. 그렇다면 Nested Loops와 Sort Merge의 장점, 특징 등을 알아보고 두 조인 방식의 단점이 무엇이길래 Hash Match가 나왔느냐에 대해 알아보는 것이 이번 주제에 대한 수순임이 분명하다.
참고:
초보들을 위해 한마디 하자면...
- 논리적인 조인이란 INNER / LEFT / FULL OUTER / 세미조인 등을 말한다.
- 여기서 설명하는 것은 그것말고 물리적인 것을 얘기하는 것이다.

(GUI 실행계획을 보면 네모친 부분을 말한다.)
2. 방식 비교
(1) 중첩반복(Nested Loops) 조인
① 그래프 실행 계획 아이콘

그래프 실행 계획 아이콘에서 보듯이 반복처리 안의 뭔가를 또 반복처리하고 있다. 유심히 보라. 괜히 만들어진 아이콘은 아니다.
② 수행 방식
아래와 같은 쿼리가 있다고 하자.
SELECT COL1, COL2
FROM TAB1 A
INNER JOIN
TAB2 B
ON A.KEY = B.KEY
WHERE A.KEY = '111'
AND A.COL1 LIKE '222%'
AND B.COL2 = '333'
Nested Loops 처리 방식을 그림으로 보면...

두가지 가정
- 옵티마이저가 통계 데이터를 보고 TAB1을 선행 테이블(먼저 읽히는 테이블)로 선택
- A.KEY, B.KEY에만 인덱스가 잡혀있다. (Non-Clustered INDEX, 클러스터드라면 인덱스 리프 페이지가 데이터 페이지라 별도의 TAB 액세스는 없을 것이다.)
1) 인덱스 페이지에서 A.KEY로 111을 찾는다. 이때, 인덱스 페이지가 KEY컬럼으로 정렬되어 있다면 스캔 방식으로 그대로 인덱스 페이지를 읽어나갈 것이고 없으면 스캔 방식으로 한번에 읽는 것이 아무래도 유리하기 때문에 정렬을 한다.
2) 인덱스 페이지에서 찾은 결과로 만약 A.KEY가 넌클러스터드 인덱스라면 RID를 통해 TAB1의 데이터 페이지를 접근하고 클러스터드 인덱스라면 리프(Leaf) 페이지가 데이터 페이지이기 때문에 별도의 데이터 페이지 접근 없음. 여기서 COL1 LIKE '222%'조건으로 한번 더 필터링 된다.
3) TAB1의 결과를 A.KEY = B.KEY 연결고리를 통해 INDEX2를 랜덤 액세스를 한다.
즉, B.KEY = '111'(데이터를 읽었기에 상수값으로 변경)로 랜덤 액세스를 한다. 이때 INDEX2(B.KEY)에 클러스터드 인덱스가 걸려 있으면 실행 계획에는 Clustered Index Seek가 뜬다. (당연한가?^^) 근데, 앞서 예시한 SQL문의 WHERE절에 B.KEY = [검색인자] 가 별도로 명시되어 있지 않음에도 실행 계획에 Clustered Index Seek가 있다는 점!!! 이런 조인 원리 모르는 사람에게는 헉~ 이건 어디서 나오는거지? 하면서 의문을 갖는 점이기도 하다.
4) TAB2에서도 2)와 동일한 방식으로 처리되어 최종 운반단위로 보내진다.
5) 반복
③ 특징 정리
- 순차적
일련의 어떤 흐름과 같이 첫 테이블 필터링에서부터 두 테이블간의 연결 및 최종 운반단위 산출까지 반복적이며 순차적으로 진행된다.
- 선행적
선행 테이블의 처리 범위가 전체 일의 양을 결정한다. 즉, 후행 테이블의 필터링 조건은 선행 테이블에서 나온 결과 ROW를 한번 더 걸러주는 체크 조건 역할을 할뿐 전체 처리량을 좌우 하는게 아니다. 다만, 부분 범위 처리를 할때 후행 테이블의 처리 범위가 넓다면 운반 단위를 빠르게 채울 수 있으므로 더 좋은 성능을 낼 수도 있다.
부연설명 하자면, 위의 예시 SQL문에서
... (생략) ...
WHERE A.KEY = '111' -- 요놈과 ...
AND A.COL1 LIKE '222%' -- 요놈이 전체 일의 양을 결정
AND B.COL2 = '333' -- 요놈은 최종 결과를 내보내기 전에 체크만 한다. 다만, 부분 범위 처리를 하고자 할 때 요놈이 없으면 빨리 빨리 운반단위를 채울 수 있으므로 더 빠를 수 있다.
- 종속적
후행 테이블은 선행 테이블의 결과값을 받아 처리된다. 즉, 선행 테이블의 결과에 종속적이다. 종속적이 되어서 나쁜 점이라고 하면 후행 테이블의 인덱스를 전체 일의 양을 줄여줄 수 있는 필터링 조건으로 사용 못한다는 점(다시 한번 강조하지만, 체크조건으로만 쓰임)이고 좋은 점은 이것을 역으로 전략적으로 이용할 수 있다는 것이다.
이런 경우를 생각해보자.
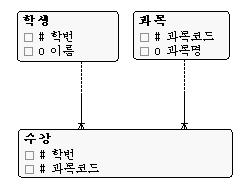
수강 테이블 : 과목코드에 Clustered Index
학생 테이블 : 학번에 Clustered Index
학생과 과목 엔터티의 관계는 M:M관계이다. 따라서, 이를 풀기 위해 수강이라는 엔터티가 도입되었다. 이때, 예를 쉽게 하기 위해 과목 엔터티는 일단 무시한다. 필자의 억지스런 예를 위해서다. :)
문제 : 자료구조(과목코드 : 000)를 수강한 모든 학생을 찾아라.
조인을 단순화하기 위해 걍 과목코드를 부여했다. 이해하시라. 그렇다면 쿼리는
SELECT 학번, 학생명
FROM 수강 A
INNER JOIN
학생 B
ON A.학번 = B.학번
WHERE A.과목코드 = 000
와 같이 될 것이다. 주어진 문제에 따르면 학생 테이블은 WHERE절을 통해 필터링 할 인덱스 컬럼이 없다. 바로 이런 경우...수강과 학생 테이블이 M:1 관계긴 하나 한 학생이 동일한 과목을 두번 수강할리는 없기에(혹 재수강? 커헉~ 그런건 없다고 가정 -_-+) 수강 테이블의 ROW수는 전교 학생들이 그 과목을 모두 수강한다해도 학생 테이블보다 똑같으면 똑같았지 클리가 없다. 따라서, 옵티마이저는 수강 테이블을 선행 테이블로 선택하고 학생 테이블을 후행 테이블로 선택한다.(아니라면 걍 그렇다고 치자. -_-;;) 이에, 수강 테이블에서 과목코드 000인 놈을 모두 찾고 같은 ROW에 학번이 있으니 그 학번으로 학생 테이블을 액세스 (즉, B.학번 = A.학번에서 수강 테이블은 읽혀졌으니 상수값으로 변경되어 B.학번 = '111', B.학번 = '222', B.학번 = '333', ... B.학번 = 'NNN' 이런 식으로)하여 Clustered Index Seek를 한다. 멋지군....짝짝짝...
- 랜덤 액세스
A.KEY = B.KEY로 선행 테이블의 결과를 통해 후행 테이블을 액세스 할때 랜덤 I/O가 발생한다. 선행 테이블은 최초 ROW만 랜덤 액세스가 발생하고 이후에는 스캔 방식으로 진행한다.
- 연결고리 중요성
A.KEY = B.KEY에서 보듯이 TAB1의 처리 ROW를 가지고 TAB2의 인덱스 페이지를 액세스하기 때문에 TAB2의 인덱스 유무가 굉장히 중요하다. 만약, TAB2에 인덱스가 없다면 옵티마이저는 TAB2를 후행 테이블로 선택하지 않는다. 다시 말해 TAB2를 선행 테이블로 선택한다. TAB2를 테이블 스캔하여 나온 결과 ROW를 가지고 인덱스가 있는 TAB1를 액세스하는게 성능면에서 유리하기 때문이다.
④ 언제 쓰면 좋은가?
- 부분 범위 처리
다른 조인 방법은 부분 범위 처리가 원천적으로 불가능하나 이 조인 방식에서는 부분 범위 처리가 가능하다. 단, MS-SQL에선 정렬을 하면 처리가 유리해진다라는 판단이 서면 서버에서 자동으로 정렬을 수행하여 사용자가 이를 제어하지 못하므로 부분범위 처리가 불가능해 질 수도 있다.
- 처리의 방향성이 필요
다른 테이블의 처리 결과를 받아야만 처리 범위를 확 줄여줄 수 있을 때 사용하면 좋다.
- 처리량이 적다.
위에서도 계속 언급한 랜덤 I/O 때문에 선행 테이블의 카디널리티를 획기적으로 줄일 수 있다면 나머지는 수학적인 반복 연결이기에 메모리를 가장 적게 사용하는 좋은 조인 방식이 된다.
이 조인 방식의 최대 단점은
두 테이블을 연결할 때의 랜덤 I/O가 가장 큰 부담이다.
(2) 정렬병합(Sort Merge) 조인
① 그래프 실행 계획 아이콘

두개의 테이블이 있고 양쪽을 합치는 듯한 표현...잘보면 재미있다.
② 수행 방식
Nested Loops에서 써먹은 쿼리를 그대로 사용하자.
SELECT COL1, COL2
FROM TAB1 A
INNER JOIN
TAB2 B
ON A.KEY = B.KEY
WHERE A.KEY = '111'
AND A.COL1 LIKE '222%'
AND B.COL2 = '333'
Sort Merge 처리 방식을 그림으로 보면...
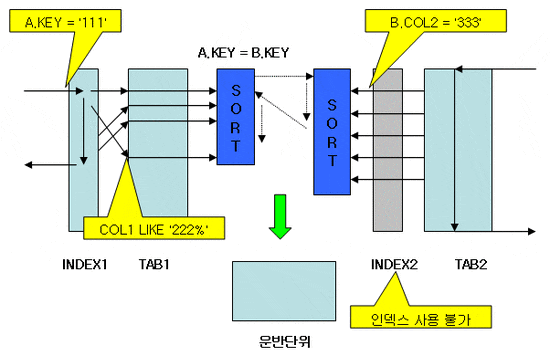
가정
- A.KEY, B.KEY에만 인덱스가 잡혀있다.
1) INDEX1에서 A.KEY가 111인 것들을 찾은 후 A.COL1 LIKE '222%'조건으로 최종 필터링된 결과행을 연결고리인 A.KEY의 값으로 정렬해둔다.
2) TAB2는 인덱스를 사용 할 수 없으므로(B.KEY로 검색하는게 없음.) TAB2를 테이블 스캔하여 B.COL2 = '333'가 만족하는 행을 연결고리인 B.KEY의 값으로 정렬해둔다. 여기서 알아둘 사항은 1)이 일어난 후 2)가 일어나는게 아니라 1)2)는 동시에 일어난다.
3) 두 개의 정렬된 결과를 가지고 A.KEY = B.KEY를 만족하는 결과를 병합(Merge)을 하면서 운반단위로 보내진다. 여기서 병합을 한다는건 양쪽 값을 스캔 방식으로 비교를 해나가다가 어느 한쪽의 값이 커지면 멈추고 커진 값을 다른 쪽 값을 비교하면서 다시 내려가는 것을 말한다. 그러다가 어느 한쪽이라도 EOF(ROW의 끝?)를 만나면 전체 처리 과정이 종료된다.
③ 특징 정리
- 동시적
Nested Loops 조인에서는 한쪽 테이블이 읽혀져야(선행 테이블) 후행 테이블을 액세스 할 수 있었다. 즉, 순차적으로 액세스 되었다. 하지만, 이 조인 방식은 양쪽 테이블을 동시에 읽고 양쪽 테이블이 조인할 준비가 되었을 때 조인을 시작한다. 즉, 어느 한쪽의 테이블의 처리가 늦어지면 다른 한쪽은 대기해야 한다.
- 독립적
Nested Loops 조인에서는 선행 테이블의 처리 결과 ROW가 후행 테이블의 연결고리의 상수값으로 사용되었다. (즉, B.KEY = '111'<- A.KEY가 읽혀져 상수값으로 변경됨) 하지만, 이 조인에서는 처리범위를 줄일 수 있는 거의 유일한 수단은 각자가 가지고 있는 필터링 조건이다. 서로의 테이블이 어떻게 필터링 됐는가는 별 관심이 없다.
- 전체 범위 처리
정렬 작업 완료 후에 조인이 일어나므로 부분 범위 처리가 되지 않는다.
- 연결고리
정렬된 양쪽 결과를 스캔하는 방식으로 조인이 일어나므로 연결고리는 크게 중요하지 않다. 그냥 사용하지 않는다고 보면 된다.
- 체크 조건의 의미
Nested Loops의 후행 테이블의 필터링 조건은 단지 선행 테이블에서 처리된 내용을 최종 운반 단위로 보낼때 그 양을 줄여주는 역할만 할뿐 전체 처리량을 줄이지는 못한다. 즉, 선행 테이블의 처리 결과 ROW수가 10건이었다하면 이 10건을 운반단위로 보내기 전에 후행 테이블의 필터링 조건을 확인하여 조건을 만족하는지 체크만 할 뿐이다. 모두가 다 만족하면 10건이 보내지겠고 만족하지 못하는 ROW가 있으면 제외가 된다. 근데, Sort Merge의 경우 인덱스를 사용하지 않는 단순 체크 조건이라도 머지할 범위를 줄여주기 때문에 상당한 의미가 있다.
④ 언제 쓰면 좋은가?
- 처리량이 많을때
Nested Loops는 처리량이 많아지면 랜덤 액세스에 대한 부담이 극심해진다. 이때 스캔방식으로 조인되는 Sort Merge를 사용하면 성능상의 이점이 있다.
- 연결고리 상태 이상
Nested Loops는 연결고리의 상태가 굉장히 중요하다고 했다. 따라서, 한쪽의 연결고리에 이상이 발생하면 Nested Loops는 심히 고려해봐야 한다. 이때, 연결고리에 영향을 받지 않는 Sort Merge를 쓰면 좋다.
이 방식의 최대 단점은
정렬에 따른 부담이다.
정렬은 tempdb를 사용한다는 사실은 누구나 알고 있다. 정렬할 양이 극도로 많아 tempdb의 임계치를 넘어버린 경우에는 tempdb에 페이지 할당이 발생하여 순간 전체 데이터베이스에 페이지 잠금이 발생하는 등 DB성능에 심각한 영향을 줄 수도 있다.
물론, 가공없이 Clustered Index를 그대로 사용하게 되면 정렬은 안해도 되니 이때만큼은 정렬의 부담에서 해방된다. 근데, Group By니 Distinct 라든지 이미 정렬된 ROW를 2차 가공하게 되면 이땐 방법이 없다. 무조건 정렬이다.
참고 :
MS-SQL에서는 양쪽 테이블에서 필터링되어 나온 값이 각 테이블에서 유니크(Unique) 할때만 이 조인 방식을 사용하려는 경향이 있다는 것을 기억하자. 연결고리로 사용할 키값에 중복이 심하면 잘 선택하지 않으려 한다.
두 조인의 단점
- Nested Loops : 랜덤 액세스
- Sort Merge : 정렬 (메모리 사용 증가)
이렇다는걸 확인 할 수 있다. 그렇다면 Hash Metch가 나온 배경이 어느 정도 짐작이 가지 싶다.
(3) 해시매치(Hash Match) 조인
① 그래프 실행 계획 아이콘
아이콘에서 보듯이 어떤 특정한 값으로 액세스하는 모양이다.
Nested Loops가 랜덤 액세스에 대한 부담이 있더라도 적은 양(대용량이라도 선행 테이블의 카디널리티를 획기적으로 줄일수만 있다면)의 데이터를 처리하기에는 이만한 조인은 없다. Sort Merge는 정렬의 부담은 있지만 연결고리에 이상이 있는 경우의 대용량을 처리하기에는 괜찮은 조인 방식이다. 문제는 정렬 자체에 있다기보다 정렬해야 할 양이 너무 많아져 tempdb의 용량을 넘어서 별도의 페이지 할당이 일어나는데 있다. 페이지 할당이 일어나면 할당 잠금이 발생하여 경합의 정도에 따라 서버가 응답하지 않을 수도 있다.
이에 해시 조인은 이 둘의 단점에 대한 대안이 될 수 있다.
② 개념 및 수행 방식
이 글을 쓰면서도 해시 조인에 대한 내용을 온라인 북과 웹(테크넷, 구글 등), 국내/국외 서적에서 찾아보았는데 정말 내용이 추상적이기만 하고 잘 설명된 서적이나 싸이트가 없었다. 물론, 위에 Nested Loops나 Sort Merge도 내용이 잘 나와 있는건 아니다. 단지, Nested Loops나 Sort Merge는 전통적인 방식이라 어느 DBMS든 비슷한 방식으로 동작 하기에 잘 설명된 내용을 기초로 적긴 했는데 Hash Match는 좀 다르단다. 요즘에도 그런지 모르나 DB2는 이 Hash Join의 개념이 없다고 하니 Hash와 관련된 상세한 원리는 Re-command를 하질 않는다나? 이건 뭔지...(이거 루머일수도 있다 주의)
일단 걍 MSSQL 온라인 북에 있는 내용을 살펴보도록 하자. 물론, 봐도 이해는 안가지 싶다.
| | |
| 해시 조인에는 빌드 입력과 검색 입력 등 두 가지 입력이 있습니다. 쿼리 최적화 프로그램은 두 가지 입력 중 작은 쪽이 빌드 입력이 될 수 있도록 이러한 역할을 할당합니다. 해시 조인은 여러 가지 유형의 집합 일치 연산, 즉 내부 조인, 왼쪽, 오른쪽, 완전 외부 조인, 왼쪽 및 오른쪽 세미 조인, 교집합, 합집합, 차집합 등에 사용합니다. 또한, 해시 조인의 변형은 중복 요소 제거 및 그룹화(예: SUM(salary) GROUP BY department)를 수행할 수 있습니다. 이러한 수정에서는 빌드 및 검색 역할 모두에 대해 한 개의 입력만 사용합니다. 다음 섹션에서는 인-메모리 해시 조인, 유예 해시 조인 및 재귀 해시 조인 등 여러 해시 조인 유형을 설명합니다.  인-메모리 해시 조인 해시 조인은 먼저 전체 빌드 입력을 스캔하거나 계산한 다음 해시 테이블을 메모리에 작성합니다. 해시 키에 대해 계산된 해시 값에 따라 각 행이 해시 버킷에 삽입됩니다. 전체 빌드 입력이 사용 가능한 메모리보다 작으면 모든 행을 해시 테이블에 삽입할 수 있습니다. 이 빌드 단계 다음으로는 검색 단계가 이어집니다. 전체 검색 입력은 한 번에 한 행씩 스캔 또는 계산되며, 각 검색 행에 대해 해시 키 값이 계산되고 해당 해시 버킷이 스캔되며 일치하는 항목이 생성됩니다. 유예 해시 조인 빌드 입력이 메모리 크기에 맞지 않으면 해시 조인은 몇 개의 단계로 진행됩니다. 이것을 유예 해시 조인이라고 합니다. 각 단계마다 빌드 단계와 검색 단계가 있습니다. 처음에는 전체 빌드 및 검색 입력이 사용되며 해시 키에 대한 해시 함수를 사용하여 여러 파일로 분할됩니다. 해시 키에 대한 해시 함수를 사용하면 2개의 조인 레코드가 모두 동일한 파일 쌍에 있는 것이 보장됩니다. 따라서 2개의 큰 입력을 조인하는 작업이 동일한 작업의 여러 개의 작은 인스턴스로 축소되었습니다. 그런 다음 해시 조인은 분할된 파일의 각 쌍에 적용됩니다. 재귀 해시 조인 빌드 입력이 너무 커서 표준 외부 병합에 대한 입력에 여러 개의 병합 수준이 필요한 경우에는 여러 개의 분할 단계와 여러 개의 분할 수준이 요구됩니다. 일부 파티션만 큰 경우에는 해당 파티션에서만 추가 분할 단계가 사용됩니다. 모든 분할 단계를 가능한 한 빠르게 유지하기 위해서는 단일 스레드가 여러 개의 디스크 드라이브를 사용 중인 상태로 유지할 수 있도록 대형의 비동기 I/O 작업이 사용됩니다. .gif) 참고: 참고: |
|---|
| 빌드 입력이 사용 가능한 메모리보다 조금밖에 크지 않다면 인-메모리 해시 조인과 유예 해시 조인의 요소가 단일 단계에서 결합되어 하이브리드 해시 조인이 생성됩니다. |
최적화 중에 사용될 해시 조인을 확인하는 것이 항상 가능한 것은 아닙니다. 따라서 SQL Server 는 빌드 입력의 크기에 따라 인-메모리 해시 조인을 사용하여 시작된 후 유예 해시 조인, 재귀 해시 조인으로 점차 전환됩니다. 2개의 입력 중 빌드 입력이 되어야 하는 작은 쪽을 최적화 프로그램이 잘못 예측하는 경우에는 빌드 및 검색 역할이 동적으로 바뀝니다. 해시 조인은 작은 쪽의 오버플로 파일을 빌드 입력으로 사용하게 합니다. 이 기술을 역할 반전이라고 합니다. 역할 반전은 하나 이상의 해시 조인이 디스크에 "spill"된 경우 해시 조인 내에서 발생합니다. | |
| | |
③ 특징 정리
- 연결고리
각 테이블의 연결고리에 있는 인덱스는 사용하지 않는다. 대신 실시간(?) 인덱스가 생성되어 그것을 통해 조인을 한다. 물론, 조인이 종료되면 삭제된다.
- 조인 결과
조인의 결과는 정렬되지 않은 상태로 출력된다. 그래서, 특정 컬럼으로 정렬을 하고 싶다면 ORDER BY절을 이용해야 한다.
- 랜덤 액세스
랜덤 액세스가 있으나 Nested Loops와는 달리 빠른 랜덤 액세스란다. (뭔 말인지...)
- 메모리 사용
해시 버켓을 만들기 위해 메모리를 꽤 사용한다.
④ 언제 쓰면 좋은가?
- 연결고리에 이상이 있거나 연결고리의 인덱스를 사용하지 못할때
Sort Merge처럼 연결고리에 인덱스가 없어도 조인을 하는데 문제가 없다.
- 소량과 대용량 테이블을 조인 할때
이 경우가 가장 좋은 성능을 낸다. 소량과 소량을 연결하는데는 차라리 Nested Loops를 쓰는게 좋다. 토깽이를 잡는데 소잡는 칼 쓸 수 없지 않은가...
3. 마치며...
Hash는 상세하게 나온게 없어서 마지막이 흐지부지 됐다. (내가 원래 그럼...-_-;;) 혹시, Hash Join에 관해 상세하게 나와 있는 곳 아시는 분 링크 좀....그리고, 잘못된 점 있으면 지적 바랍니다.
스크롤 압박에도 여까지 읽어주시니 감사할 따름이지요.